When I tell people I am learning Bayesian statistics, I tend to get one of two responses: either people look at me blankly—“What’s Bayesian statistics?”—or I get scorned for using such “loose” methods—“Bayesian analysis is too subjective!”1. This latter “concern” arises due to (what I believe to be a misunderstanding of) the prior: Bayesian analysis requires one state what one’s prior belief is about a certain effect, and then combine this with the data observed (i.e., the likelihood) to update one’s belief (the posterior).
On the face of it, it might seem odd for a scientific method to include “subjectivity” in its analysis. I certainly had this doubt when I first started learning it. (And, in order to be honest with myself, I still struggle with it sometimes.) But, the more I read, the more I think this concern is not warranted, as the prior is not really “subjectivity” in the strictest sense of the word at all: it is based on our current understanding of the effect we are interested in, which in turn is (often) based on data we have seen before. Yes, sometimes the prior can be a guess if we2 have no other information to go on, but we would express the uncertainty of a belief in the prior itself.
The more I understand Bayesian statistics, the more I appreciate the prior is essential. One under-stated side-effect of having priors is that it can protect you from dubious findings. For example, I have a very strong prior against UFO predictions; therefore, you are going to have to present me with a lot more evidence than some shaky video footage to convince me otherwise. You would not have to provide me with much evidence, however, if you claimed to have roast beef last night. Extraordinary claims require extraordinary evidence.
But, during my more sceptical hours, I often succumbed to the the-prior-is-nothing-but-subjectivity-poisoning-your-analysis story. However, I now believe that even if one is sceptical of the use of a prior, there are a few things to note:
- If you are concerned your prior is wrong and is influencing your inferences, just collect more data: A poorly-specified prior will be washed away with sufficient data.
-
The prior isn’t (really) subjective because it would have to be justified to a sceptical audience. This requires (I suggest) plotting what the prior looks like so readers can familiarise themselves with your prior. Is it really subjective if I show you what my prior looks like and I can justify it?
-
Related to the above, the effect of the prior can be investigated using robustness checks, where one plots the posterior distribution based on a range of (plausible) prior values. If your conclusions don’t depend upon the exact prior used, what’s the problem?
-
Priors are not fixed. Once you have collected some data and have a posterior belief, if you wish to examine the effect further you can (and should) use the posterior from the previous study as your prior for the next study.
These are the points I mention to anti-Bayesians I encounter. In this blog I just wanted to skip over some of these with examples. This is selfish; it’s not really for your education (there really are better educators out there: My recommendation is Alex Etz’s excellent “Understanding Bayes” series, from where this blog post takes much inspiration!). I just want somewhere with all of this written down so next time someone criticises my interest in Bayesian analysis I can just reply: “Read my blog!”. (Please do inform me of any errors/misconceptions by leaving a comment!)
As some readers might not be massively familiar with these issues, I try to highlight some of the characteristics of the prior below. In all of these examples, I will use the standard Bayesian “introductory tool” of assessing the degree of bias in a coin by observing a series of flips.
A Fair Coin
If a coin is unbiased, it should produce roughly equal heads and tails. However, often we don’t know whether a coin is biased or not. We wish to estimate the bias in the coin (denoted theta) by collecting some data (i.e., by flipping the coin); a fair coin has a theta = 0.5. Based on this data, we can calculate the likelihood of various theta values. Below is the likelihood function for a fair coin.

In this example, we flipped the coin 100 times, and observed 50 heads and 50 tails. Note how the peak of the likelihood is centered on theta = 0.5. A biased coin would have a true theta not equal to 0.5; theta closer to zero would reflect a bias towards tails, and a theta closer to 1 would reflect a bias towards heads. The animation below demonstrates how the likelihood changes as the number of observed heads (out of 100 flips) increases:
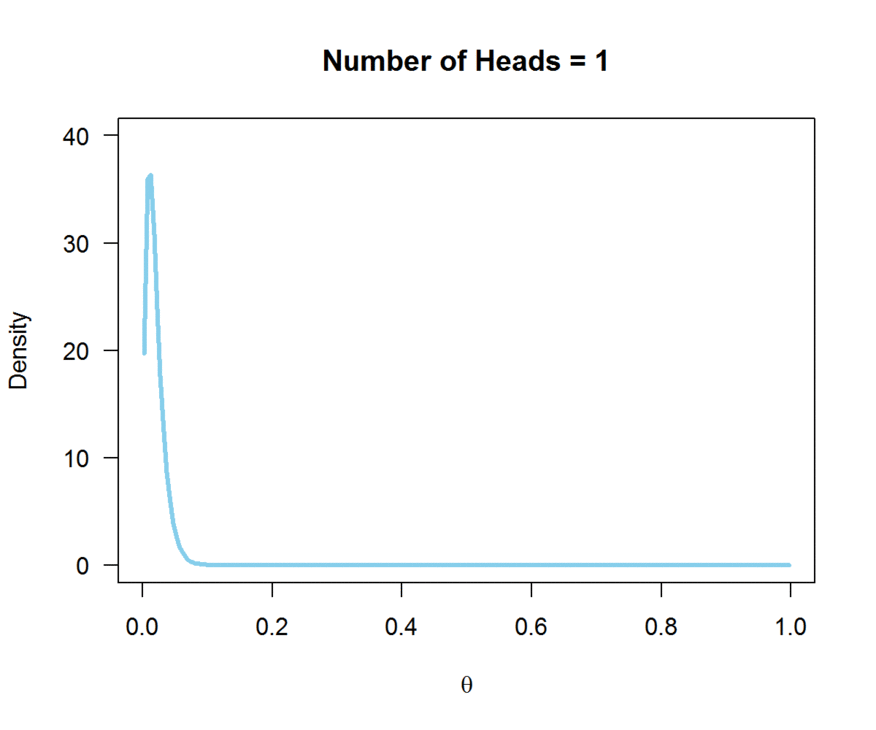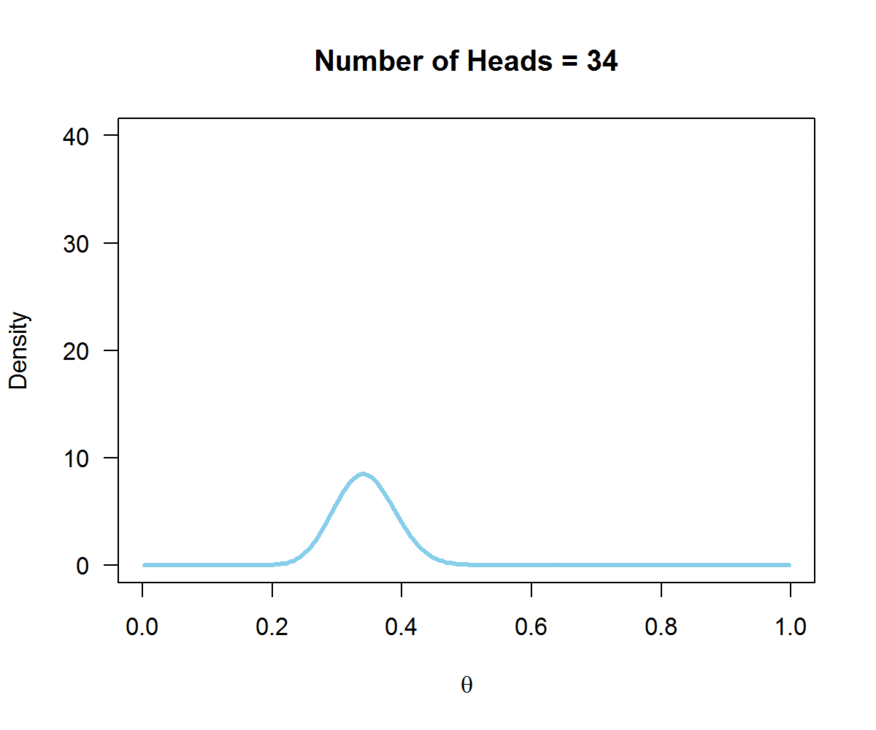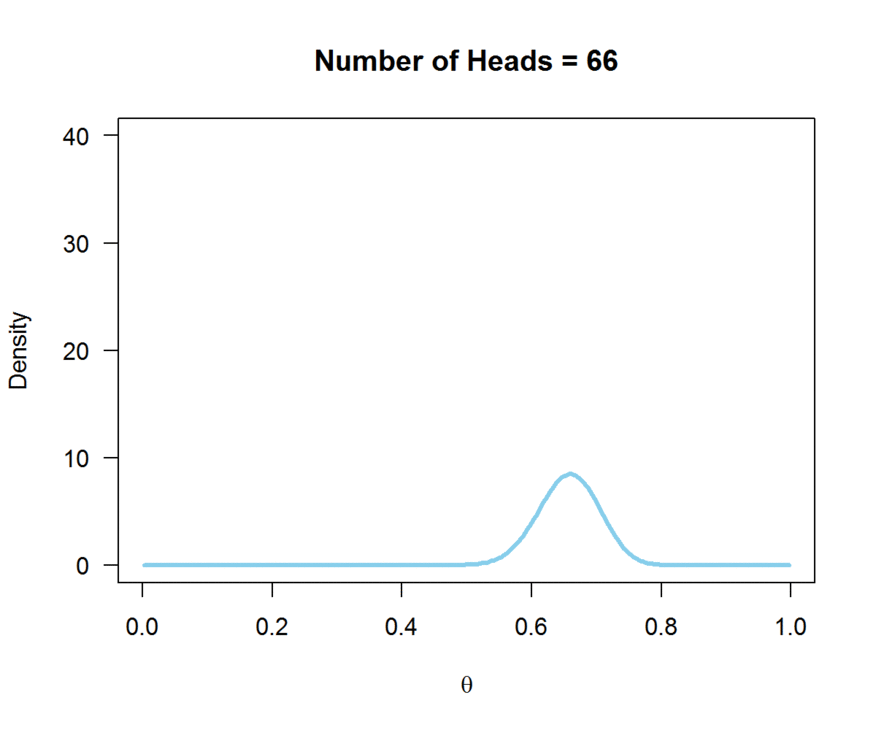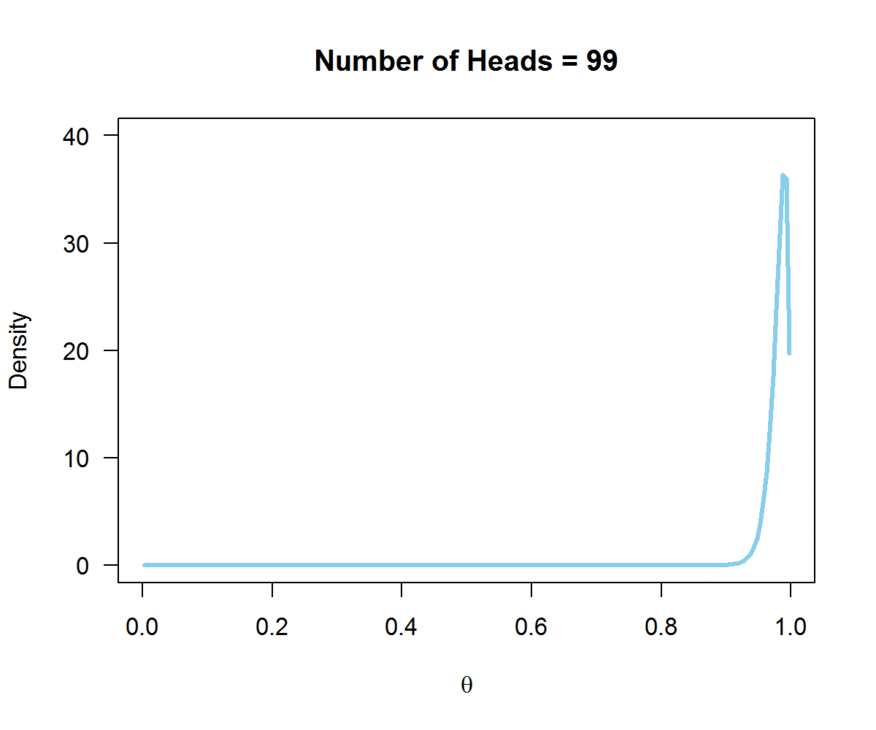
So, the likelihood contains the information provided by our sample about the true value for theta.
The Prior
Before collecting data, Bayesian analysts would specify what their prior belief was about theta. Below I present various priors a Bayesian may have using the beta distribution (which has two parameters: a and b):
The upper left plot reflects a prior belief that the coin is fair (i.e., the peak of the distribution is centered over theta = 0.5); however, there is some uncertainty in this prior as the distribution has some spread. The upper right plot reflects total uncertainty in a prior belief: that is, the prior holds that any value of theta is likely. The lower two plots reflect prior beliefs that the coin is biased. Maybe the researcher had obtained the coin from a known con-artist. The lower left plot reflects a prior for a biased coin, but uncertainty about which side the coin is biased towards (that is, it could be biased heads or tails); the lower right plot reflects a prior that the coin is biased towards heads.
The effect of the prior
I stated above that one of the benefits of the prior is that it allows protection (somewhat) from spurious findings. If I have a really strong prior belief that the coin is fair, 9/10 heads isn’t going to be all that convincing evidence that it is not fair. However, if I have a weak prior that the coin is fair, then I will be quite convinced by the data.
This is illustrated below. Both priors below reflect the belief that the coin is fair; what differs between the two is the strength in this belief. The prior on the left is quite a weak belief, as the distribution (although peaked at 0.5) is quite spread out. The prior on the right is a stronger belief that the coin is fair.
In both cases, the likelihood is the result of observing 9/10 heads.

You can see that when the prior is a weak belief, the posterior is very similar to the likelihood; that is, the posterior belief is almost entirely dictated by the data. However, when we have a strong prior belief, our beliefs are not altered much by observing just 9/10 heads.
Now, I imagine that this is the anti-Bayesian’s point: “Even with clear data you haven’t changed your mind.” True. Is this a negative? Well, imagine instead this study was assessing the existence of UFOs rather than simple coin flips. If I showed you 9 YouTube videos of UFO “evidence”, and 1 video showing little (if any) evidence, would you be convinced of UFOs? I doubt it. You were the right-hand plot in this case. (I know, I know, the theta distribution doesn’t make sense in this case, but ignore that!)
What if the prior is wrong?
Worried that your prior is wrong3, or that you cannot justify it completely? Throw more data at it. (When is this ever a bad idea?) Below are the same priors, but now we flip the coin 1,000 times and observe 900 heads. (Note, the proportion heads is the same in the previous example.) Now, even our strong prior belief has to be updated considerably based on this data. With more data, even mis-specified priors do not affect inference.

To get an idea of how sample size influences the effect of the prior on the posterior, I created the below gif animation. In it, we have a relatively strong (although not insanely so) prior belief that the coin is biased “heads”. Then, we start flipping the coin, and update the posterior after each flip. In fact, this coin is fair, so our prior is not in accord with (unobservable) “reality”. As flips increases, though, our posterior starts to match the likelihood in the data. So, “wrong” priors aren’t really a problem. Just throw more data at it.

“Today’s posterior is tomorrow’s prior” — Lindley (1970)
After collecting some data and updating your prior, you now have a posterior belief of something. If you wish to collect more data, you do not use your original prior (because it no longer reflects your belief), but you instead use the posterior from your previous study as the prior for your current one. Then, you collect some data, update your priors into your posteriors…and so on.
In this sense, Bayesian analysis is ultimately “self-correcting”: as you collect more and more data, even horrendously-specified priors won’t matter.
In the example below, we have a fairly-loose idea that the coin is fair—i.e., theta = 0.5. We flip a coin 20 times, and observe 18 heads. Then we update to our posterior, which suggests the true value for theta is about 0.7 ish. But then we wish to run a second “study”; we use the posterior from study 1 as our prior for study 2. We again observe 18 heads out of 20 flips, and update accordingly.

Conclusion
One of the nicest things about Bayesian analysis is that the way our beliefs should be updated in the face of incoming data is clearly (and logically) specified. Many peoples’ concerns surround the prior. I hope I have shed some light on why I do not consider this to be a problem. Even if the prior isn’t something that should be “overcome” with lots of data, it is reassuring to know for the anti–Bayesian that with sufficient data, it doesn’t really matter much.
So, stop whining about Bayesian analysis, and go collect more data. Always, more data.
Click here for the R code for this post
- Occasionally (althought his is happening more and more) I get a slow, wise, agreeing nod. I like those. ↩
- I really wanted to avoid the term “we””, as it implies I am part of the “in-group”: those experts of Bayesian analysis who truly appreciate all of its beauty, and are able to apply it to all of their experimental data. I most certainly do not fall into this camp; but I am trying. ↩
- Technically, it cannot be “wrong” because it is your belief. If that belief is justifiable, then it’s all-game. You may have to update your prior though if considerable data contradict it. But, bear with me. ↩

I’m still not convinced. I would much prefer to have independent confirmation of an experimental finding, rather than using today’s posterior as tomorrow’s prior.
I contend that you can get a long way by the common sense assumption that it’s not legitimate to assume a prior probability that there is a real effect greater then 0.5. This enables you to put a lower limit on the false positive rate (or what a Bayesian would call the posterior distribution). This can be done without any subjective element. I think omission of this from elementary statistics courses has made a substantial contribution to the crisis in reproducibility: http://rsos.royalsocietypublishing.org/content/1/3/140216
Thank you for your comment and for the link! I will have a look at that paper.
Thanks. I’ll be interested to hear your reaction.
I love seeing more stats/Bayes gifs! Keep it up. Quick comment:
I think if you really do have a reason to believe that the coin is possibly fair (theta=.5, or some other *particular* value), you should assign some initial amount of probability to that value specifically. All of these priors are continuous distributions, which really assign probability of zero to the possibility of a fair coin (or any particular value of theta for that matter). Essentially what you’ve done here is assumed it is in fact definitely biased, but that you are uncertain about the extent of bias!
I was going to make a quip about true/wrong priors, but then I saw footnote 3. 🙂
Thanks for comment. I think this is why I find Bayesians’ insistence on using the coin-flipping example difficult, because values other than 0, 0.5, and 1 don’t make much intuitive sense (compared to some other DV where theta values along a continuous range are more interpretable).
Yes, footnote 3: That was in response to a comment from you when I first showed the 2nd gif on Twitter 🙂
Nice post and good looking graphs! 🙂
“Bayesian analysis requires one state what one’s prior belief is about a certain effect”
I also used to say this, but I made a change to this sentence that makes it make more sense, both to me and to people I try to introduce Bayes to. The change is this:
“Bayesian analysis requires one state what the model’s prior belief is about a certain effect”
Which is actually what you do in a sense, as it’s practically impossible to encode what your actual (brain based) belief is using the language of mathematics, while it’s completely possible to run a Bayesian model that doesn’t reflect your beliefs at all. Then it is of course possible to build a model that models your beliefs… 🙂
Ah, good point – I like that! Thanks for the comment.